基础语法
helloword
from bcc import BPF
BPF(text='int kprobe__sys_sync(void *ctx) { bpf_trace_printk("sys_sync() called\\n"); return 0; }').trace_print()int kprobe__sys_sync(void *ctx)
{
bpf_trace_printk("sys_sync() called\\n");
return 0;
}kprobe是什么?
是一种可以跟踪内核函数执行状态的轻量级内核调试技术,简单来说就是内核插桩技术
当内核运行到该探测点后可以执行用户预定义的回调函数,以收集所需的调试状态信息而基本不影响内核原有的执行流程
强大的eBPF特性也寄生于kprobe之上
kprobes探测手段
kprobes技术包括3种探测手段分别为kprobe、jprobe和kretprobe,其中:
kprobe是最基本的探测方式,是实现后两种的基础,它可以在内核的任何指令位置插入探测点;
jprobe基于kprobe实现,只能插入到一个内核函数的入口,它用于获取被探测函数的入参值;
kretprobe也是基于kprobe实现,可以在指定的内核函数返回时才被执行。利用该方式可以获取被探测函数的返回值,还可以用于计算函数执行时间等方面
总结:
kprobe --- inline hook
jprobe --- frida onstart
kretprobe --- frida onleave
工作流程
1)注册kprobe。注册的每个kprobe对应一个kprobe结构体,该结构中记录着插入点(位置),以及该插入点本来对应的指令original_opcode;
2)替换原有指令。使能kprobe的时候,将插入点位置的指令替换为一条异常(BRK)指令,这样当CPU执行到插入点位置时会陷入到异常态;
3)执行pre_handler。进入异常态后,首先执行pre_handler,然后利用CPU提供的单步调试(single-step)功能,设置好相应的寄存器,将
下一条指令设置为插入点处本来的指令,从异常态返回;
4)再次陷入异常态。上一步骤中设置了single-step相关的寄存器,所以originnal_opcode刚一执行,便会二进宫:再次陷入异常态,此时将single-step
清除,并且执行post_handler,然后从异常态安全返回。
总结:
类似于基于异常的hook方式
kprobe总结
一种内核插桩工具,ebpf基于这个工具
这里kprobe__sys_clone() : 函数是指使用kprobe对sys_clone系统调用进行hook,触发这个hook之后回执行函数体里的内容
bpf中的printf - bpf_trace_printk
函数原型
long bpf_trace_printk(const char *fmt, __u32 fmt_size, …);
作用
将信息输出到/sys/kernel/debug/tracing/trace_pipe
sudo cat /sys/kernel/debug/tracing/trace_pipe 即可完成读取
这里trace_print就是为了读取输出才执行的
hellofields
from __future__ import print_function
from bcc import BPF
from bcc.utils import printb
# load BPF program
b = BPF(text="""
#include <uapi/linux/ptrace.h>
BPF_HASH(last);
int do_trace(struct pt_regs *ctx) {
u64 ts, *tsp, delta, key = 0;
// attempt to read stored timestamp
tsp = last.lookup(&key);
if (tsp != NULL) {
delta = bpf_ktime_get_ns() - *tsp;
if (delta < 1000000000) {
// output if time is less than 1 second
bpf_trace_printk("%d\\n", delta / 1000000);
}
last.delete(&key);
}
// update stored timestamp
ts = bpf_ktime_get_ns();
last.update(&key, &ts);
return 0;
}
""")
b.attach_kprobe(event=b.get_syscall_fnname("sync"), fn_name="do_trace")
print("Tracing for quick sync's... Ctrl-C to end")
# format output
start = 0
while 1:
try:
(task, pid, cpu, flags, ts, ms) = b.trace_fields()
if start == 0:
start = ts
ts = ts - start
printb(b"At time %.2f s: multiple syncs detected, last %s ms ago" % (ts, ms))
except KeyboardInterrupt:
exit()理解
对hello_word程序进行了拆解,便于再不同的阶段执行不同的操作。
首先定义一个bpf程序存入prog参数中,这个程序于hello_word中的ebpf程序不同的是,并不会自动hook 内核函数,只是一个普通的bpf函数,注意所有的bpf函数都需要传入ctx参数即使不用
b = BPF(text=prog)可以把这个程序加载到内核中
b.attach_kprobe(event=b.get_syscall_fnname(“clone”), fn_name=“hello”)可以指定同时hook不同的内核函数,并执行不同的回调函数,这应该是整个代码这样写的优点
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
这个需要记住输出了那些参数,分别指的是什么
这里新增加两个API需要理解
- BPF_HASH(last);
- bpf_ktime_get_ns()
bpf_ktime_get_ns
用于获取一个毫秒级的时间
BPF_HASH
在eBPF(Extended Berkeley Packet Filter)程序中定义一个名为last的哈希表的简洁方式
相关操作API
// 用于查找这个名为last的哈希表中的键,找到了就会返回一个指向对应值的指针
// 如果没有找到,它会返回 NULL
tsp = last.lookup(&key);
// 向hash表中新增加一个键值对
last.update(&key, &ts);
// 删除键值对
last.delete(&key);sync_timing - PULS
重写了一下这个案例遇到挺多语法问题,首先如何看产生的报错是什么,同时定位报错位置。
如下所示,程序会对每一行代码的作用进行分析,这里再分析到add = 1 + (*tmp);产生报错,所以根据报错我们就知道,由于再解引用之前没对指针是否为空进行判断。
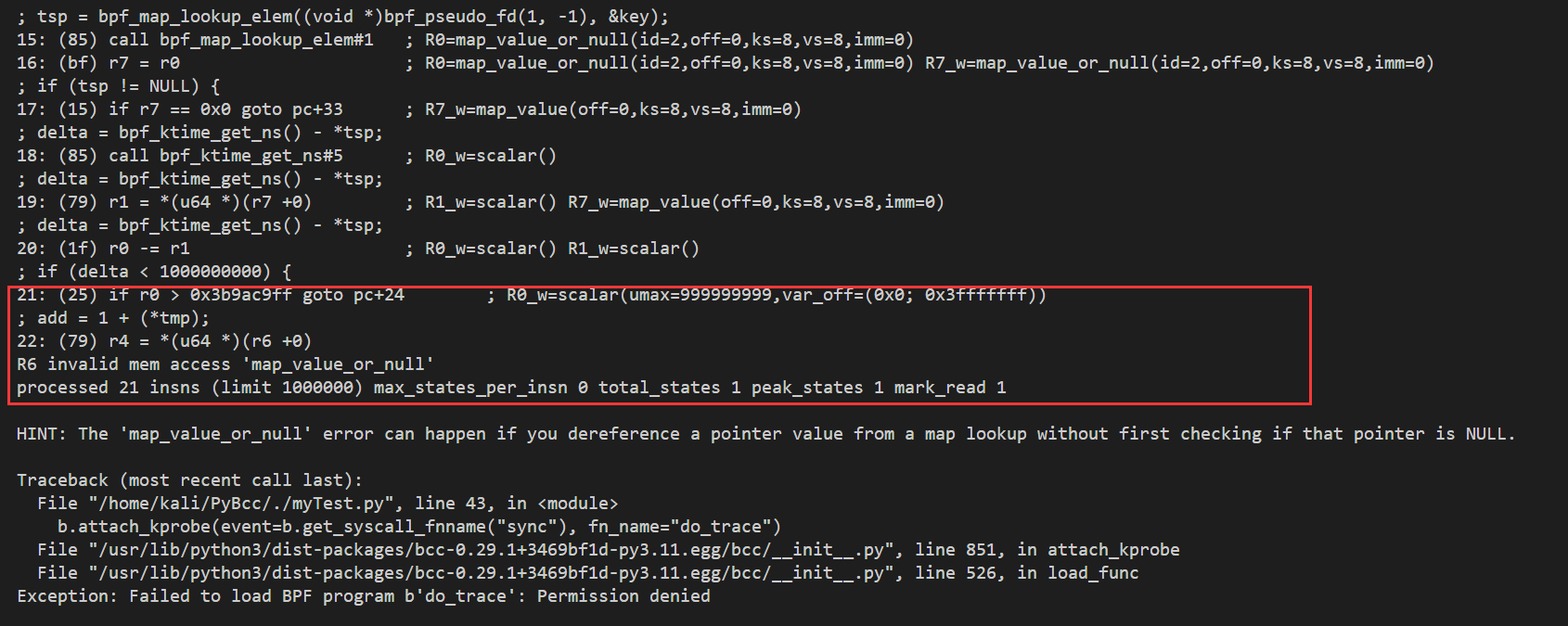
修改后的代码如下,主要是添加了一个计数器的参数,体会了BPF_HASH的用法
from __future__ import print_function
from bcc import BPF
from bcc.utils import printb
# load BPF program
b = BPF(text="""
#include <uapi/linux/ptrace.h>
BPF_HASH(last);
int do_trace(struct pt_regs *ctx) {
u64 ts, *tsp, delta, key = 0;
// attempt to read stored timestamp
tsp = last.lookup(&key);
if (tsp != NULL) {
delta = bpf_ktime_get_ns() - *tsp;
if (delta < 1000000000) {
// output if time is less than 1 second
bpf_trace_printk("%d\\n", delta / 1000000);
}
last.delete(&key);
}
// update stored timestamp
ts = bpf_ktime_get_ns();
last.update(&key, &ts);
return 0;
}
""")
b.attach_kprobe(event=b.get_syscall_fnname("sync"), fn_name="do_trace")
print("Tracing for quick sync's... Ctrl-C to end")
# format output
start = 0
while 1:
try:
(task, pid, cpu, flags, ts, ms) = b.trace_fields()
if start == 0:
start = ts
ts = ts - start
printb(b"At time %.2f s: multiple syncs detected, last %s ms ago" % (ts, ms))
except KeyboardInterrupt:
exit()sync_timing
from __future__ import print_function
from bcc import BPF
from bcc.utils import printb
REQ_WRITE = 1 # from include/linux/blk_types.h
# load BPF program
b = BPF(text="""
#include <uapi/linux/ptrace.h>
#include <linux/blk-mq.h>
BPF_HASH(start, struct request *);
void trace_start(struct pt_regs *ctx, struct request *req) {
// stash start timestamp by request ptr
u64 ts = bpf_ktime_get_ns();
start.update(&req, &ts);
}
void trace_completion(struct pt_regs *ctx, struct request *req) {
u64 *tsp, delta;
tsp = start.lookup(&req);
if (tsp != 0) {
delta = bpf_ktime_get_ns() - *tsp;
bpf_trace_printk("%d %x %d\\n", req->__data_len,
req->cmd_flags, delta / 1000);
start.delete(&req);
}
}
""")
# b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
# b.attach_kprobe(event="blk_account_io_completion", fn_name="trace_completion")
# header
print("%-18s %-2s %-7s %8s" % ("TIME(s)", "T", "BYTES", "LAT(ms)"))
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
(bytes_s, bflags_s, us_s) = msg.split()
if int(bflags_s, 16) & REQ_WRITE:
type_s = b"W"
elif bytes_s == "0": # see blk_fill_rwbs() for logic
type_s = b"M"
else:
type_s = b"R"
ms = float(int(us_s, 10)) / 1000
printb(b"%-18.9f %-2s %-7s %8.2f" % (ts, type_s, bytes_s, ms))
except KeyboardInterrupt:
exit()理解
主要是在c语言代码层面的函数参数
void trace_completion(struct pt_regs *ctx, struct request *req)
可以发现多了一个参数,这个参数就是要hook的函数的参数,基本上与unicorn的hook差不多,不过多解释。
这里内核版本有点高,有的函数已经不被使用了
hello_perf_output
from bcc import BPF
# define BPF program
prog = """
#include <linux/sched.h>
// define output data structure in C
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
};
BPF_PERF_OUTPUT(events);
int hello(struct pt_regs *ctx) {
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
bpf_get_current_comm(&data.comm, sizeof(data.comm));
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# process event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %s" % (time_s, event.comm, event.pid,
"Hello, perf_output!"))
# loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while 1:
b.perf_buffer_poll()总结
主要是提供了一种,内核程序与应用层通信的手段。
在内核层定义一个BPF_PERF_OUTPUT
// 定义了一个名为events的BPF性能事件输出数组,用于将收集到的数据发送到用户空间。
BPF_PERF_OUTPUT(events);然后再往里面传入数据,传入数据的api如下
// 将data结构体中的数据输出到用户空间
events.perf_submit(ctx, &data, sizeof(data));再应用层接收,下面这个函数设置了接收的回调函数,b中的键名就是内核层中的BPF_PERF_OUTPUT内的名字
b["events"].open_perf_buffer(print_event)回调函数注意参数就行
# process event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %s" % (time_s, event.comm, event.pid,
"Hello, perf_output!"))最后的while循环用于做卡住进程,等待内核层的消息
while 1:
b.perf_buffer_poll()实现目标
监测调用 Linux 系统调用的行为
https://cloud.tencent.com/developer/article/2016433
https://github.com/pmem/vltrace/blob/master/src/ebpf_syscalls.c
https://lwn.net/Articles/645169/
// SPDX-License-Identifier: GPL-2.0-only OR MIT
/*
Copyright (C) 2023 The Falco Authors.
This file is dual licensed under either the MIT or GPL 2. See MIT.txt
or GPL2.txt for full copies of the license.
*/
#include "quirks.h"
#include <generated/utsrelease.h>
#include <uapi/linux/bpf.h>
#if __has_include(<asm/rwonce.h>)
#include <asm/rwonce.h>
#endif
#include <linux/sched.h>
#include "../driver_config.h"
#include "../ppm_events_public.h"
#include "bpf_helpers.h"
#include "types.h"
#include "maps.h"
#include "plumbing_helpers.h"
#include "ring_helpers.h"
#include "filler_helpers.h"
#include "fillers.h"
#include "builtins.h"
// 用于创建段
#ifdef BPF_SUPPORTS_RAW_TRACEPOINTS
#define BPF_PROBE(prefix, event, type) \
__bpf_section(TP_NAME #event) \
int bpf_##event(struct type *ctx)
#else
#define BPF_PROBE(prefix, event, type) \
__bpf_section(TP_NAME prefix #event) \
int bpf_##event(struct type *ctx)
#endif
// 在Linux内核中表示32位系统中的socketcall系统调用的编号
#define __NR_ia32_socketcall 102
// 这段代码是一个BPF程序,用于在Linux内核中拦截系统调用,并对其进行处理。具体来说,它会在每
// 次系统调用进入内核时被调用,然后根据系统调用的类型和参数,决定是否对其进行处理。
// 该程序首先获取系统调用的编号,然后根据该编号判断是否需要进行32位到64位的转换。如果是32位
// 系统调用,则需要将其转换为64位系统调用,以便在64位系统上运行。如果是64位系统调用,则直接
// 进行处理。
// 接下来,程序会根据系统调用的编号判断是否需要对其进行处理。如果该系统调用是感兴趣的系统调用
// ,则会获取该系统调用的相关信息,并根据该信息决定是否对其进行处理。如果该系统调用不是感兴趣
// 的系统调用,则会直接跳过处理。
// 最后,程序会调用一个名为“call_filler”的函数,该函数会对系统调用进行处理,并将处理结果返
// 回给内核。具体的处理方式取决于系统调用的类型和参数,以及程序的具体实现。
BPF_PROBE("raw_syscalls/", sys_enter, sys_enter_args)
{
const struct syscall_evt_pair *sc_evt = NULL;
ppm_event_code evt_type = -1;
int drop_flags = 0;
long id = 0;
bool enabled = false;
int socketcall_syscall_id = -1;
id = bpf_syscall_get_nr(ctx);
if (id < 0 || id >= SYSCALL_TABLE_SIZE)
return 0;
if (bpf_in_ia32_syscall())
{
// Right now we support 32-bit emulation only on x86.
// We try to convert the 32-bit id into the 64-bit one.
#if defined(CONFIG_X86_64) && defined(CONFIG_IA32_EMULATION)
if (id == __NR_ia32_socketcall)
{
socketcall_syscall_id = __NR_ia32_socketcall;
}
else
{
id = convert_ia32_to_64(id);
// syscalls defined only on 32 bits are dropped here.
if(id == -1)
{
return 0;
}
}
#else
// Unsupported arch
return 0;
#endif
}
else
{
// Right now only s390x supports it
#ifdef __NR_socketcall
socketcall_syscall_id = __NR_socketcall;
#endif
}
// Now all syscalls on 32-bit should be converted to 64-bit apart from `socketcall`.
// This one deserves a special treatment
if(id == socketcall_syscall_id)
{
#ifdef BPF_SUPPORTS_RAW_TRACEPOINTS
bool is_syscall_return = false;
int return_code = convert_network_syscalls(ctx, &is_syscall_return);
if (return_code == -1)
{
// Wrong SYS_ argument passed. Drop the syscall.
return 0;
}
if(!is_syscall_return)
{
evt_type = return_code;
drop_flags = UF_USED;
}
else
{
id = return_code;
}
#else
// We do not support socketcall when raw tracepoints are not supported.
return 0;
#endif
}
// In case of `evt_type!=-1`, we need to skip the syscall filtering logic because
// the actual `id` is no longer representative for this event.
// There could be cases in which we have a `PPME_SOCKET_SEND_E` event
// and`id=__NR_ia32_socketcall`...We resolved the correct event type but we cannot
// update the `id`.
if (evt_type == -1)
{
enabled = is_syscall_interesting(id);
if(!enabled)
{
return 0;
}
sc_evt = get_syscall_info(id);
if(!sc_evt)
return 0;
if(sc_evt->flags & UF_USED)
{
evt_type = sc_evt->enter_event_type;
drop_flags = sc_evt->flags;
}
else
{
evt_type = PPME_GENERIC_E;
drop_flags = UF_ALWAYS_DROP;
}
}
#ifdef BPF_SUPPORTS_RAW_TRACEPOINTS
call_filler(ctx, ctx, evt_type, drop_flags, socketcall_syscall_id);
#else
/* Duplicated here to avoid verifier madness */
struct sys_enter_args stack_ctx;
memcpy(stack_ctx.args, ctx->args, sizeof(ctx->args));
if (stash_args(stack_ctx.args))
return 0;
call_filler(ctx, &stack_ctx, evt_type, drop_flags, socketcall_syscall_id);
#endif
return 0;
}
BPF_PROBE("raw_syscalls/", sys_exit, sys_exit_args)
{
const struct syscall_evt_pair *sc_evt = NULL;
ppm_event_code evt_type = -1;
int drop_flags = 0;
long id = 0;
bool enabled = false;
struct scap_bpf_settings *settings = 0;
long retval = 0;
int socketcall_syscall_id = -1;
id = bpf_syscall_get_nr(ctx);
if (id < 0 || id >= SYSCALL_TABLE_SIZE)
return 0;
if (bpf_in_ia32_syscall())
{
#if defined(CONFIG_X86_64) && defined(CONFIG_IA32_EMULATION)
if (id == __NR_ia32_socketcall)
{
socketcall_syscall_id = __NR_ia32_socketcall;
}
else
{
/*
* When a process does execve from 64bit to 32bit, TS_COMPAT is marked true
* but the id of the syscall is __NR_execve, so to correctly parse it we need to
* use 64bit syscall table. On 32bit __NR_execve is equal to __NR_ia32_oldolduname
* which is a very old syscall, not used anymore by most applications
*/
#ifdef __NR_execveat
if(id != __NR_execve && id != __NR_execveat)
#else
if(id != __NR_execve)
#endif
{
id = convert_ia32_to_64(id);
if(id == -1)
{
return 0;
}
}
}
#else
// Unsupported arch
return 0;
#endif
}
else
{
#ifdef __NR_socketcall
socketcall_syscall_id = __NR_socketcall;
#endif
}
if(id == socketcall_syscall_id)
{
#ifdef BPF_SUPPORTS_RAW_TRACEPOINTS
bool is_syscall_return = false;
int return_code = convert_network_syscalls(ctx, &is_syscall_return);
if (return_code == -1)
{
// Wrong SYS_ argument passed. Drop the syscall.
return 0;
}
if(!is_syscall_return)
{
evt_type = return_code + 1; // we are in sys_exit!
drop_flags = UF_USED;
}
else
{
id = return_code;
}
#else
// We do not support socketcall when raw tracepoints are not supported.
return 0;
#endif
}
if(evt_type == -1)
{
enabled = is_syscall_interesting(id);
if(!enabled)
{
return 0;
}
sc_evt = get_syscall_info(id);
if(!sc_evt)
return 0;
if(sc_evt->flags & UF_USED)
{
evt_type = sc_evt->exit_event_type;
drop_flags = sc_evt->flags;
}
else
{
evt_type = PPME_GENERIC_X;
drop_flags = UF_ALWAYS_DROP;
}
}
settings = get_bpf_settings();
if (!settings)
return 0;
// Drop failed syscalls if necessary
if (settings->drop_failed)
{
retval = bpf_syscall_get_retval(ctx);
if (retval < 0)
{
return 0;
}
}
#if defined(CAPTURE_SCHED_PROC_FORK) || defined(CAPTURE_SCHED_PROC_EXEC)
if(bpf_drop_syscall_exit_events(ctx, evt_type))
return 0;
#endif
call_filler(ctx, ctx, evt_type, drop_flags, socketcall_syscall_id);
return 0;
}
BPF_PROBE("sched/", sched_process_exit, sched_process_exit_args)
{
ppm_event_code evt_type;
struct task_struct *task;
unsigned int flags;
task = (struct task_struct *)bpf_get_current_task();
flags = _READ(task->flags);
if (flags & PF_KTHREAD)
return 0;
evt_type = PPME_PROCEXIT_1_E;
call_filler(ctx, ctx, evt_type, UF_NEVER_DROP, -1);
return 0;
}
BPF_PROBE("sched/", sched_switch, sched_switch_args)
{
ppm_event_code evt_type;
evt_type = PPME_SCHEDSWITCH_6_E;
call_filler(ctx, ctx, evt_type, 0, -1);
return 0;
}
#ifdef CAPTURE_PAGE_FAULTS
static __always_inline int bpf_page_fault(struct page_fault_args *ctx)
{
ppm_event_code evt_type;
evt_type = PPME_PAGE_FAULT_E;
call_filler(ctx, ctx, evt_type, UF_ALWAYS_DROP, -1);
return 0;
}
BPF_PROBE("exceptions/", page_fault_user, page_fault_args)
{
return bpf_page_fault(ctx);
}
BPF_PROBE("exceptions/", page_fault_kernel, page_fault_args)
{
return bpf_page_fault(ctx);
}
#endif
BPF_PROBE("signal/", signal_deliver, signal_deliver_args)
{
ppm_event_code evt_type;
evt_type = PPME_SIGNALDELIVER_E;
call_filler(ctx, ctx, evt_type, UF_ALWAYS_DROP, -1);
return 0;
}
#ifndef BPF_SUPPORTS_RAW_TRACEPOINTS
__bpf_section(TP_NAME "sched/sched_process_fork&1")
int bpf_sched_process_fork(struct sched_process_fork_args *ctx)
{
ppm_event_code evt_type;
struct sys_stash_args args;
unsigned long *argsp;
argsp = __unstash_args(ctx->parent_pid);
if (!argsp)
return 0;
memcpy(&args, argsp, sizeof(args));
__stash_args(ctx->child_pid, args.args);
return 0;
}
#endif
#ifdef CAPTURE_SCHED_PROC_EXEC
BPF_PROBE("sched/", sched_process_exec, sched_process_exec_args)
{
struct scap_bpf_settings *settings;
/* We will always send an execve exit event. */
ppm_event_code event_type = PPME_SYSCALL_EXECVE_19_X;
/* We are not interested in kernel threads. */
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
unsigned int flags = _READ(task->flags);
if(flags & PF_KTHREAD)
{
return 0;
}
/* Reset the tail context in the CPU state map. */
uint32_t cpu = bpf_get_smp_processor_id();
struct scap_bpf_per_cpu_state * state = get_local_state(cpu);
if(!state)
{
return 0;
}
settings = get_bpf_settings();
if(!settings)
{
return 0;
}
uint64_t ts = settings->boot_time + bpf_ktime_get_boot_ns();
reset_tail_ctx(state, event_type, ts);
++state->n_evts;
int filler_code = PPM_FILLER_sched_prog_exec;
bpf_tail_call(ctx, &tail_map, filler_code);
bpf_printk("Can't tail call filler 'sched_proc_exec' evt=%d, filler=%d\n",
event_type,
filler_code);
return 0;
}
#endif /* CAPTURE_SCHED_PROC_EXEC */
#ifdef CAPTURE_SCHED_PROC_FORK
__bpf_section("raw_tracepoint/sched_process_fork&2")
int bpf_sched_process_fork(struct sched_process_fork_raw_args *ctx)
{
struct scap_bpf_settings *settings;
/* We will always send a clone exit event. */
ppm_event_code event_type = PPME_SYSCALL_CLONE_20_X;
/* We are not interested in kernel threads. */
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
unsigned int flags = _READ(task->flags);
if(flags & PF_KTHREAD)
{
return 0;
}
/* Reset the tail context in the CPU state map. */
uint32_t cpu = bpf_get_smp_processor_id();
struct scap_bpf_per_cpu_state * state = get_local_state(cpu);
if(!state)
{
return 0;
}
settings = get_bpf_settings();
if(!settings)
{
return 0;
}
uint64_t ts = settings->boot_time + bpf_ktime_get_boot_ns();
reset_tail_ctx(state, event_type, ts);
++state->n_evts;
int filler_code = PPM_FILLER_sched_prog_fork;
bpf_tail_call(ctx, &tail_map, filler_code);
bpf_printk("Can't tail call filler 'sched_proc_fork' evt=%d, filler=%d\n",
event_type,
filler_code);
return 0;
}
#endif /* CAPTURE_SCHED_PROC_FORK */
char kernel_ver[] __bpf_section("kernel_version") = UTS_RELEASE;
char __license[] __bpf_section("license") = "Dual MIT/GPL";
char probe_ver[] __bpf_section("probe_version") = DRIVER_VERSION;
char probe_commit[] __bpf_section("build_commit") = DRIVER_COMMIT;
uint64_t probe_api_ver __bpf_section("api_version") = PPM_API_CURRENT_VERSION;
uint64_t probe_schema_ver __bpf_section("schema_version") = PPM_SCHEMA_CURRENT_VERSION;Syscall hook
import os
from bcc import BPF
import psutil
DEBUG = 0
procName = "traceSVCTest00"
# 定义系统调用
SYSCALLS_NUMBERS = {
0: "read",
1: "write",
2: "open",
3: "close",
4: "stat",
5: "fstat",
6: "lstat",
7: "poll",
8: "lseek",
9: "mmap",
10: "mprotect",
11: "munmap",
12: "brk",
13: "rt_sigaction",
14: "rt_sigprocmask",
15: "rt_sigreturn",
16: "ioctl",
17: "pread",
18: "pwrite",
19: "readv",
20: "writev",
21: "access",
22: "pipe",
23: "select",
24: "sched_yield",
25: "mremap",
26: "msync",
27: "mincore",
28: "madvise",
29: "shmget",
30: "shmat",
31: "shmctl",
32: "dup",
33: "dup2",
34: "pause",
35: "nanosleep",
36: "getitimer",
37: "alarm",
38: "setitimer",
39: "getpid",
40: "sendfile",
41: "socket",
42: "connect",
43: "accept",
44: "sendto",
45: "recvfrom",
46: "sendmsg",
47: "recvmsg",
48: "shutdown",
49: "bind",
50: "listen",
51: "getsockname",
52: "getpeername",
53: "socketpair",
54: "setsockopt",
55: "getsockopt",
56: "clone",
57: "fork",
58: "vfork",
59: "execve",
60: "exit",
61: "wait4",
62: "kill",
63: "uname",
64: "semget",
65: "semop",
66: "semctl",
67: "shmdt",
68: "msgget",
69: "msgsnd",
70: "msgrcv",
71: "msgctl",
72: "fcntl",
73: "flock",
74: "fsync",
75: "fdatasync",
76: "truncate",
77: "ftruncate",
78: "getdents",
79: "getcwd",
80: "chdir",
81: "fchdir",
82: "rename",
83: "mkdir",
84: "rmdir",
85: "creat",
86: "link",
87: "unlink",
88: "symlink",
89: "readlink",
90: "chmod",
91: "fchmod",
92: "chown",
93: "fchown",
94: "lchown",
95: "umask",
96: "gettimeofday",
97: "getrlimit",
98: "getrusage",
99: "sysinfo",
100: "times",
101: "ptrace",
102: "getuid",
103: "syslog",
104: "getgid",
105: "setuid",
106: "setgid",
107: "geteuid",
108: "getegid",
109: "setpgid",
110: "getppid",
111: "getpgrp",
112: "setsid",
113: "setreuid",
114: "setregid",
115: "getgroups",
116: "setgroups",
117: "setresuid",
118: "getresuid",
119: "setresgid",
120: "getresgid",
121: "getpgid",
122: "setfsuid",
123: "setfsgid",
124: "getsid",
125: "capget",
126: "capset",
127: "rt_sigpending",
128: "rt_sigtimedwait",
129: "rt_sigqueueinfo",
130: "rt_sigsuspend",
131: "sigaltstack",
132: "utime",
133: "mknod",
134: "uselib",
135: "personality",
136: "ustat",
137: "statfs",
138: "fstatfs",
139: "sysfs",
140: "getpriority",
141: "setpriority",
142: "sched_setparam",
143: "sched_getparam",
144: "sched_setscheduler",
145: "sched_getscheduler",
146: "sched_get_priority_max",
147: "sched_get_priority_min",
148: "sched_rr_get_interval",
149: "mlock",
150: "munlock",
151: "mlockall",
152: "munlockall",
153: "vhangup",
154: "modify_ldt",
155: "pivot_root",
156: "_sysctl",
157: "prctl",
158: "arch_prctl",
159: "adjtimex",
160: "setrlimit",
161: "chroot",
162: "sync",
163: "acct",
164: "settimeofday",
165: "mount",
166: "umount2",
167: "swapon",
168: "swapoff",
169: "reboot",
170: "sethostname",
171: "setdomainname",
172: "iopl",
173: "ioperm",
174: "create_module",
175: "init_module",
176: "delete_module",
177: "get_kernel_syms",
178: "query_module",
179: "quotactl",
180: "nfsservctl",
181: "getpmsg",
182: "putpmsg",
183: "afs_syscall",
184: "tuxcall",
185: "security",
186: "gettid",
187: "readahead",
188: "setxattr",
189: "lsetxattr",
190: "fsetxattr",
191: "getxattr",
192: "lgetxattr",
193: "fgetxattr",
194: "listxattr",
195: "llistxattr",
196: "flistxattr",
197: "removexattr",
198: "lremovexattr",
199: "fremovexattr",
200: "tkill",
201: "time",
202: "futex",
203: "sched_setaffinity",
204: "sched_getaffinity",
205: "set_thread_area",
206: "io_setup",
207: "io_destroy",
208: "io_getevents",
209: "io_submit",
210: "io_cancel",
211: "get_thread_area",
212: "lookup_dcookie",
213: "epoll_create",
214: "epoll_ctl_old",
215: "epoll_wait_old",
216: "remap_file_pages",
217: "getdents64",
218: "set_tid_address",
219: "restart_syscall",
220: "semtimedop",
221: "fadvise64",
222: "timer_create",
223: "timer_settime",
224: "timer_gettime",
225: "timer_getoverrun",
226: "timer_delete",
227: "clock_settime",
228: "clock_gettime",
229: "clock_getres",
230: "clock_nanosleep",
231: "exit_group",
232: "epoll_wait",
233: "epoll_ctl",
234: "tgkill",
235: "utimes",
236: "vserver",
237: "mbind",
238: "set_mempolicy",
239: "get_mempolicy",
240: "mq_open",
241: "mq_unlink",
242: "mq_timedsend",
243: "mq_timedreceive",
244: "mq_notify",
245: "mq_getsetattr",
246: "kexec_load",
247: "waitid",
248: "add_key",
249: "request_key",
250: "keyctl",
251: "ioprio_set",
252: "ioprio_get",
253: "inotify_init",
254: "inotify_add_watch",
255: "inotify_rm_watch",
256: "migrate_pages",
257: "openat",
258: "mkdirat",
259: "mknodat",
260: "fchownat",
261: "futimesat",
262: "newfstatat",
263: "unlinkat",
264: "renameat",
265: "linkat",
266: "symlinkat",
267: "readlinkat",
268: "fchmodat",
269: "faccessat",
270: "pselect6",
271: "ppoll",
272: "unshare",
273: "set_robust_list",
274: "get_robust_list",
275: "splice",
276: "tee",
277: "sync_file_range",
278: "vmsplice",
279: "move_pages",
280: "utimensat",
281: "epoll_pwait",
282: "signalfd",
283: "timerfd",
284: "eventfd",
285: "fallocate",
286: "timerfd_settime",
287: "timerfd_gettime",
288: "accept4",
289: "signalfd4",
290: "eventfd2",
291: "epoll_create1",
292: "dup3",
293: "pipe2",
294: "inotify_init1",
295: "preadv",
296: "pwritev",
297: "rt_tgsigqueueinfo",
298: "perf_event_open",
299: "recvmmsg",
300: "fanotify_init",
301: "fanotify_mark",
302: "prlimit64",
303: "name_to_handle_at",
304: "open_by_handle_at",
305: "clock_adjtime",
306: "syncfs",
307: "sendmmsg",
308: "setns",
309: "getcpu",
310: "process_vm_readv",
311: "process_vm_writev",
312: "kcmp",
313: "finit_module",
314: "sched_setattr",
315: "sched_getattr",
316: "renameat2",
317: "seccomp",
318: "getrandom",
319: "memfd_create",
320: "kexec_file_load",
321: "bpf",
322: "execveat",
323: "userfaultfd",
324: "membarrier",
325: "mlock2",
326: "copy_file_range",
327: "preadv2",
328: "pwritev2",
329: "pkey_mprotect",
330: "pkey_alloc",
331: "pkey_free",
332: "statx",
333: "io_pgetevents",
334: "rseq",
}
# procName = "systemd"
# 获取pid
def get_proc_info(name):
return [p.info for p in psutil.process_iter(['pid', 'name']) if name in p.info['name']]
# 通过pid获取可执行文件路径
def get_process_path(pid):
return os.readlink(f'/proc/{pid}/exe')
# test 注意对长度进行判断来验证是否获取到pid
procInfo = get_proc_info(procName)
if len(procInfo) != 0:
procPid = str(procInfo[0]['pid'])
procPath = get_process_path(procPid)
print(f"{procPath}存在, PID:{procPid}")
else:
print("目标进程不存在")
exit(-1)
# 监控系统调用
prog = """
#include <uapi/linux/ptrace.h>
struct data_t {
u32 pid;
u64 syscall_id;
};
BPF_PERF_OUTPUT(syscall_events);
TRACEPOINT_PROBE(raw_syscalls, sys_enter) {
u32 pid = bpf_get_current_pid_tgid();
if (pid == ###PID###) {
u64 ts = bpf_ktime_get_ns();
struct data_t data = {};
data.pid = pid;
data.syscall_id = args->id;
syscall_events.perf_submit(args, &data, sizeof(data));
}
return 0;
}
"""
prog = prog.replace('###PID###',procPid)
if DEBUG:
print(prog)
else:
# 加载并运行eBPF程序 去除debug的警告
b = BPF(text=prog)
def print_event(cpu, data, size):
syscall_events = b["syscall_events"].event(data)
syscall_id_str = SYSCALLS_NUMBERS[syscall_events.syscall_id]
print("pid: %d syscall_id: %s" % (syscall_events.pid, syscall_id_str))
# b.attach_uprobe(name=procPath, sym="function__entry", fn_name="function_entry")
# b.attach_uprobe(name=procPath, sym="function__return", fn_name="function_return")
b["syscall_events"].open_perf_buffer(print_event)
# b.trace_print()
while 1:
b.perf_buffer_poll()struct data_t {
u32 pid;
int depth;
u64 addr;
u64 syscall_id;
};
BPF_PERF_OUTPUT(syscall_events);
BPF_HASH(function_start, u32);
BPF_HASH(entrypoints, u32, int);
TRACEPOINT_PROBE(raw_syscalls, sys_enter) {
u32 pid = bpf_get_current_pid_tgid();
if (pid == ###PID###) {
u64 ts = bpf_ktime_get_ns();
struct data_t data = {};
data.pid = pid;
data.syscall_id = args->id;
// data.addr = PT_REGS_IP(ctx);
int *depth_ptr = entrypoints.lookup(&pid);
if (depth_ptr != 0) {
data.depth = *depth_ptr;
}
else{
data.depth = 0;
}
syscall_events.perf_submit(args, &data, sizeof(data));
}
return 0;
}
int function_entry(struct pt_regs *ctx) {
u32 pid = bpf_get_current_pid_tgid();
if(pid == ###PID###){
u64 ts = bpf_ktime_get_ns();
function_start.update(&pid, &ts);
int depth = 0;
int *depth_ptr = entrypoints.lookup(&pid);
if (depth_ptr != 0) {
depth = *depth_ptr + 1;
}else{
depth = 0;
}
entrypoints.update(&pid, &depth);
}
return 0;
}
int function_return(struct pt_regs *ctx) {
u32 pid = bpf_get_current_pid_tgid();
u64 *tsp = function_start.lookup(&pid);
if (tsp == 0) {
return 0; // missed start
}
int depth = 0;
int *depth_ptr = entrypoints.lookup(&pid);
if (depth_ptr != 0) {
depth = *depth_ptr - 1;
}else{
depth = 0;
}
entrypoints.update(&pid, &depth);
return 0;
}流量监控
from socket import *
from struct import pack
from bcc import BPF
from ctypes import *
import sys
def help():
print("execute: {0} <net_interface>".format(sys.argv[0]))
print("e.g.: {0} eno1\n".format(sys.argv[0]))
exit(1)
if len(sys.argv) != 2:
help()
elif len(sys.argv) == 2:
INTERFACE = sys.argv[1]
bpf_text = """
#include <bcc/proto.h>
#define IP_TCP 6
#define IP_UDP 17
#define IP_ICMP 1
#define ETH_HLEN 14
struct data_t {
u32 saddr;
u32 daddr;
char proto[16];
};
BPF_PERF_OUTPUT(net_events);
int packet_monitor(struct __sk_buff *skb) {
struct data_t data = {};
u8 *cursor = 0;
struct ethernet_t *ethernet = cursor_advance(cursor, sizeof(*ethernet));
struct ip_t *ip = cursor_advance(cursor, sizeof(*ip));
data.saddr = ip->src;
data.daddr = ip->dst;
if (ip->nextp == IP_TCP) {
__builtin_memcpy(data.proto, "TCP", 4);
} else if (ip->nextp == IP_UDP) {
__builtin_memcpy(data.proto, "UDP", 4);
} else if (ip ->nextp == IP_ICMP){
__builtin_memcpy(data.proto, "ICMP", 5);
} else{
__builtin_memcpy(data.proto, "Other", 6);
}
net_events.perf_submit(skb, &data, sizeof(data));
return 0;
}
"""
bpf = BPF(text=bpf_text)
function_skb_matching = bpf.load_func("packet_monitor", BPF.SOCKET_FILTER)
BPF.attach_raw_socket(function_skb_matching, INTERFACE)
def print_event(cpu, data, size):
event = bpf["net_events"].event(data)
print("Source IP: %s" % inet_ntop(AF_INET, pack("I", event.saddr)))
print("Destination IP: %s" % inet_ntop(AF_INET, pack("I", event.daddr)))
print("Protocol: %s" % event.proto)
bpf["net_events"].open_perf_buffer(print_event)
while True:
try:
bpf.perf_buffer_poll()
except KeyboardInterrupt:
exit()from socket import *
from struct import pack
from bcc import BPF
from ctypes import *
import sys
def help():
print("execute: {0} <net_interface>".format(sys.argv[0]))
print("e.g.: {0} eno1\n".format(sys.argv[0]))
exit(1)
if len(sys.argv) != 2:
help()
elif len(sys.argv) == 2:
INTERFACE = sys.argv[1]
bpf_text = """
#include <bcc/proto.h>
#define IP_TCP 6
#define IP_UDP 17
#define IP_ICMP 1
#define ETH_HLEN 14
struct data_t {
u32 saddr;
u32 daddr;
char proto[16];
};
BPF_PERF_OUTPUT(net_events);
int packet_monitor(struct __sk_buff *skb) {
struct data_t data = {};
u8 *cursor = 0;
struct ethernet_t *ethernet = cursor_advance(cursor, sizeof(*ethernet));
struct ip_t *ip = cursor_advance(cursor, sizeof(*ip));
data.saddr = ip->src;
data.daddr = ip->dst;
if (ip->nextp == IP_TCP) {
__builtin_memcpy(data.proto, "TCP", 4);
} else if (ip->nextp == IP_UDP) {
__builtin_memcpy(data.proto, "UDP", 4);
} else if (ip ->nextp == IP_ICMP){
__builtin_memcpy(data.proto, "ICMP", 5);
} else{
__builtin_memcpy(data.proto, "Other", 6);
}
net_events.perf_submit(skb, &data, sizeof(data));
return 0;
}
"""
bpf = BPF(text=bpf_text)
function_skb_matching = bpf.load_func("packet_monitor", BPF.SOCKET_FILTER)
BPF.attach_raw_socket(function_skb_matching, INTERFACE)
def print_event(cpu, data, size):
event = bpf["net_events"].event(data)
print("Source IP: %s" % inet_ntop(AF_INET, pack("I", event.saddr)))
print("Destination IP: %s" % inet_ntop(AF_INET, pack("I", event.daddr)))
print("Protocol: %s" % event.proto)
bpf["net_events"].open_perf_buffer(print_event)
while True:
try:
bpf.perf_buffer_poll()
except KeyboardInterrupt:
exit()参考链接:
https://www.freebuf.com/column/208928.html
https://www.cnblogs.com/Mang0/p/13878654.html
http://kerneltravel.net/project/
https://l0n9w4y.cc/posts/11235/
https://www.kernel.org/doc/html/latest/bpf/index.html
https://nakryiko.com/posts/libbpf-bootstrap/
https://github.com/eunomia-bpf/bpf-developer-tutorial
https://github.com/libbpf/libbpf-bootstrap
https://zhuanlan.zhihu.com/p/630098056
https://github.com/eunomia-bpf/libbpf-starter-template
https://github.com/iovisor/bcc/blob/master/docs/reference_guide.md?spm=a2c6h.12873639.article-detail.7.14833ba5iwgkqU&file=reference_guide.md